さくらインターネットさんが実施している「生成AI全力応援キャンペーン」に申し込んでみました。なんと、高火力VRTと呼ばれるGPU演算が可能なサーバーを 100時間無料 で利用できるとのことです。
以前より、ローカル環境でDeepSeekのモデルを動かして遊んでいましたが、CPUで動かすモデルはやはり簡単な応答しかできません。もっと大きなモデルをエッジ環境で動かしてみたいと思い、今回試してみることにしました。
高火力VRTは「さくらのクラウド」上で起動でき、石狩第1ゾーンで利用が可能です。
余談ですが、当社は以前、さくらインターネットさんの石狩データセンターをお借りしてお客様のBCP計画を支援したことがあります。見学に伺った際、その設備の美しさと整然さに感動したのを覚えています。そこで今、NVIDIAのH100がたくさん動いていると思うと、感慨深いものがあります。
今回のステップ
話がそれましたが、今回の手順はとてもシンプルです。 わずか3ステップでAIをローカル環境で動かすことができました。
- さくらのクラウドでサーバーを作成する
- Ollamaをインストールする
- OllamaでGPT-OSSモデルをダウンロードして実行する
オープンソースのGPTモデルについて
ChatGPTを提供するOpenAIが、オープンソースモデルとして公開した gpt-oss を動かします。 現在、以下の2つのモデルがあります。
- gpt-oss-20b:CPUでも動作する21Bパラメータの小規模モデル
- gpt-oss-120b:117Bパラメータを持つ大規模モデル(GPU必須)
いずれも蒸留モデルですが、詳細な説明はここでは割愛します。
Ollamaについて
AIモデルがあっても、それを呼び出すためのツールが必要です。今回は、ローカル環境で大規模言語モデル(LLM)を簡単に実行・管理できるオープンソースツール Ollama を利用します。OllamaはWindowsやMacなどでGUIが提供されますが、CLIでも実行可能で今回それを利用します。
類似ツールとしては、LM Studio や vLLM なども有名です。
さくらのクラウドの利用
当社は以前からさくらのクラウドを利用しており、アカウントを保有しています。 まだアカウントをお持ちでない方は、以下の公式マニュアルを参照してください。
https://manual.sakura.ad.jp/cloud/payment/signup.html
なお、高火力VRTを用いて第三者にサービスを提供する場合は、規約上の申請が必要とのことです。今回は自分用の実験利用なので問題ありません。
https://manual.sakura.ad.jp/cloud/server/gpu-plan.html
さくらのクラウドにログインするとクラウドホームから「さくらのクラウド」メニューを選択します。

次にコンソール上から「石狩第1ゾーン」を選択します。
そして、サーバを作成(追加)します。このサーバーはAWSで言うところのEC2にあたります。
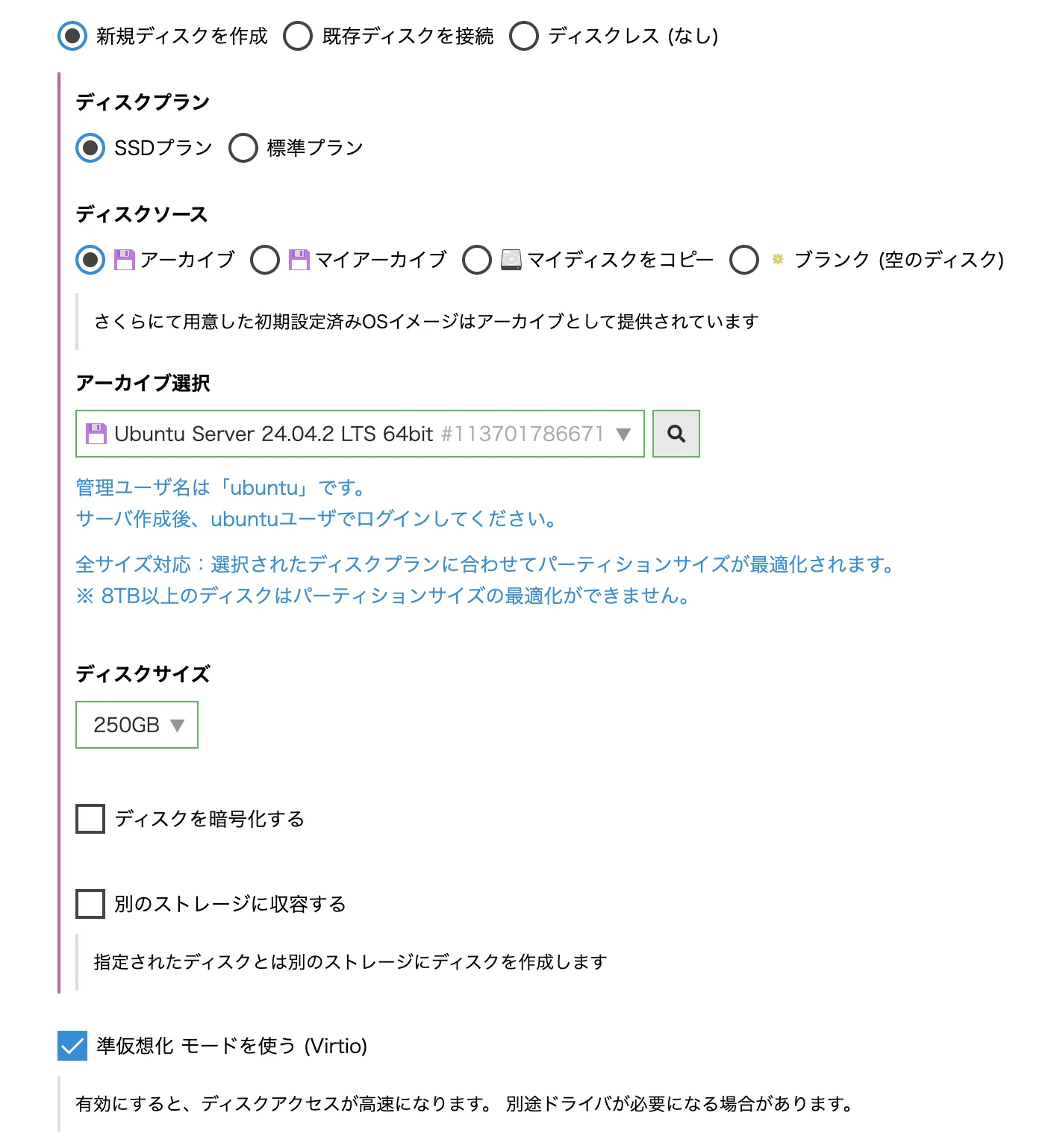
作成するサーバのパラメータを決めてきます。仮想コアといわれるコンピューティングリソース部分を選びます。ここでは「高火力VRT(GPU)プラン」を選択します。また、このプランにはV100とH100のものがあり、H100の方が新しいGPUとなるのでこちらを選択します。

次にディスクを選択します。AWSでいうとEBSにあたるものです。今回動かそうとしているChatGPTのオープンモデルが容量(65GB程度)があることから余裕がある容量を選びます。また、アーカイブ選択でOSの種類を選択します。今回はUbuntu Serverを選択しました。
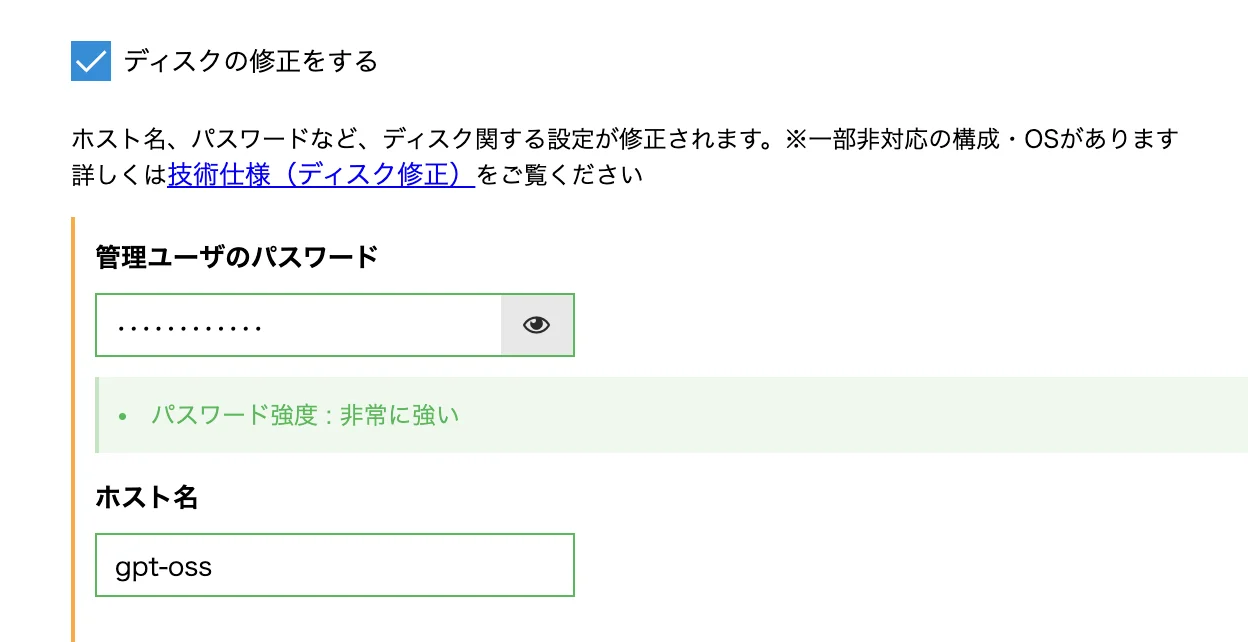
次に管理者ユーザのパスワードとホスト名を決めます。ここではホスト名は「gpt-oss」としておきます。
最後に「作成」を押すとサーバが作成されます。
サーバーが作成されていきます。
作成が完了したら「閉じる」を押します。
サーバが作成されていることを確認します。IPアドレスを確認してください。

SSHで接続してログイン出来ればサーバの作成は完了です。
ssh ubuntu@153.120.25.47
Ollamaのインストール
Ollamaのインストールは公式サイトにアクセスします。
https://ollama.com/download/linux
今回のさくらのクラウドのサーバーはOSをUbuntuを選択しているのでLinux版を選択します。
WEBサイトに以下の案内があるので、コピーしてSSHコンソール上で実行します。
curl -fsSL https://ollama.com/install.sh | sh
ChatGPTモデルのダウンロード
ChatGPTモデルは実はOllamaを実行するとモデルが自動的にダウンロードされます。
以下のコマンドでモデルのダウンロードと実行が可能です。
ollama run gpt-oss:120b
ダウンロードとモデルの読み込みに時間がかかるので少し待ちます。
対話式のプロンプトが帰ってきたら、あとは言語モデルと会話が行えます。

高火力VRTのH100について
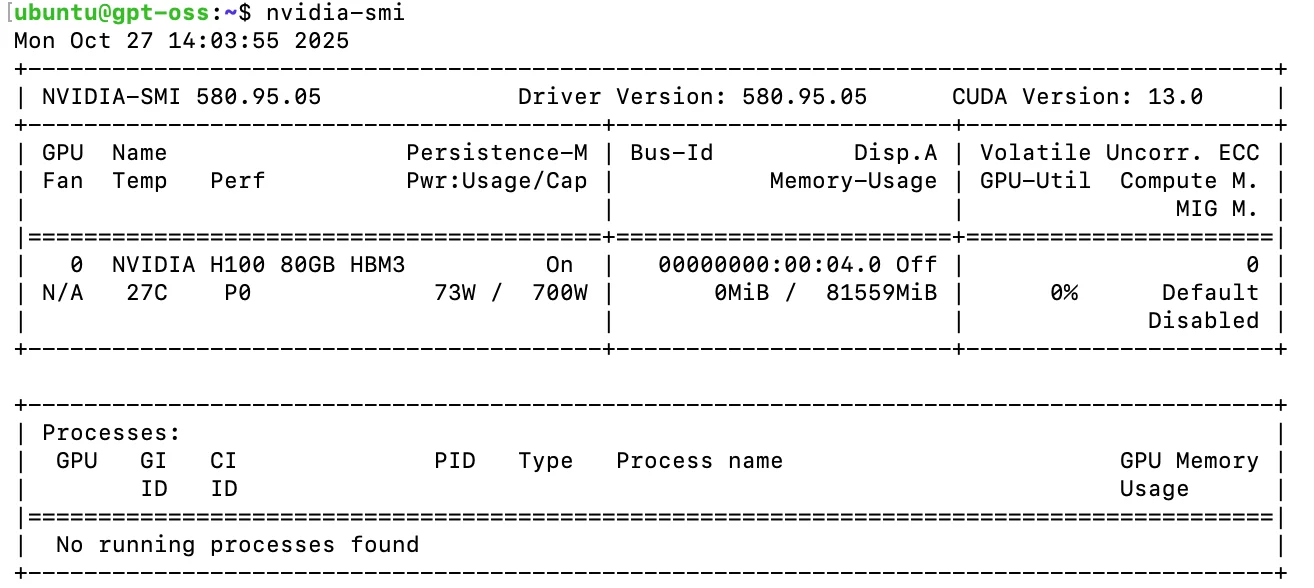
さくらのクラウドに搭載されているNVIDIAのH100について以下のコマンドで確認をしてみました。
nvidia-smi
消費電力やメモリ量などが確認出来ます。
GPT-OSSモデルを動かしてみて
実際に動かしてみてまず感じたのは、とにかく 速い ということです。オンライン版ChatGPTに慣れていると、ローカル実行のレスポンスの速さと安定性には驚かされます。自分専用リソースのため、応答遅延がほとんどありません。
Ollamaはサーバーモードにも対応しており、Webアプリなどから呼び出すことも可能です。 複数人で利用する場合は当然負荷が増えますが、個人用のChatGPTとして使うには非常に快適です。H100を個人用途で占有するのは採算が合いませんが、ノートPCで動く軽量モデルの登場を期待させる体験でした。
コストについて
今回利用した高火力VRT(H100)の料金は以下の通りです(2025年10月27日時点・当社調べ)。
| 時割 | 1,037円 |
|---|---|
| 日割 | 23,581円 |
| 月額 | 394,625円 |
ストレージ料金は別途発生します。
個人利用としてはかなり高価ですが、蒸留モデルの作成や強化学習、独自モデルの実行といった研究・開発用途では十分に価値があると感じます。同等スペックのAWS EC2と比較すると、為替や価格改定にもよりますが、やや安価に利用できる印象です。
さくらのクラウドについて
当社はAWS APNとして活動しているため、普段はAWSを中心に利用しています。CDKを用いたデプロイが定常化している現在、今回のようにさくらのクラウドを触ることで、サーバーの基本的な強さと手触りを改めて感じました。
どちらが優れているかではなく、用途に応じて選択肢を持つことが重要です。今後も当社では、AWS・さくらインターネット双方のソリューションを積極的に検証・採用していきたいと考えています。
ローカルマシンでの動作について
後日談として、手元のM4 MacBook Pro(メモリ128GB)およびM4 MacBook Air(メモリ32GB)でも動作検証を行ってみました。 驚いたことに、MacBook Proでは「gpt-oss:128b」が非常にスムーズに動作しました。
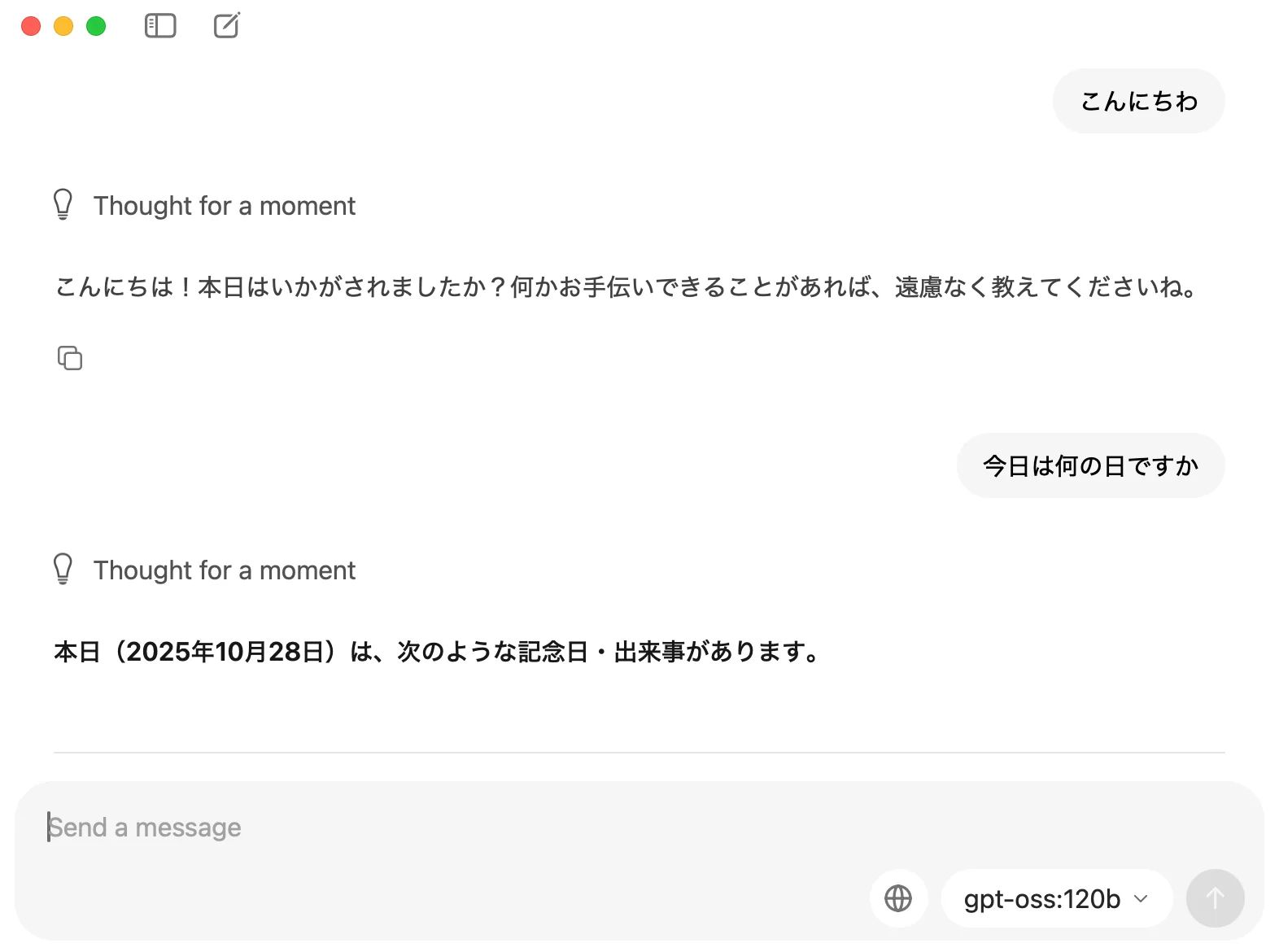
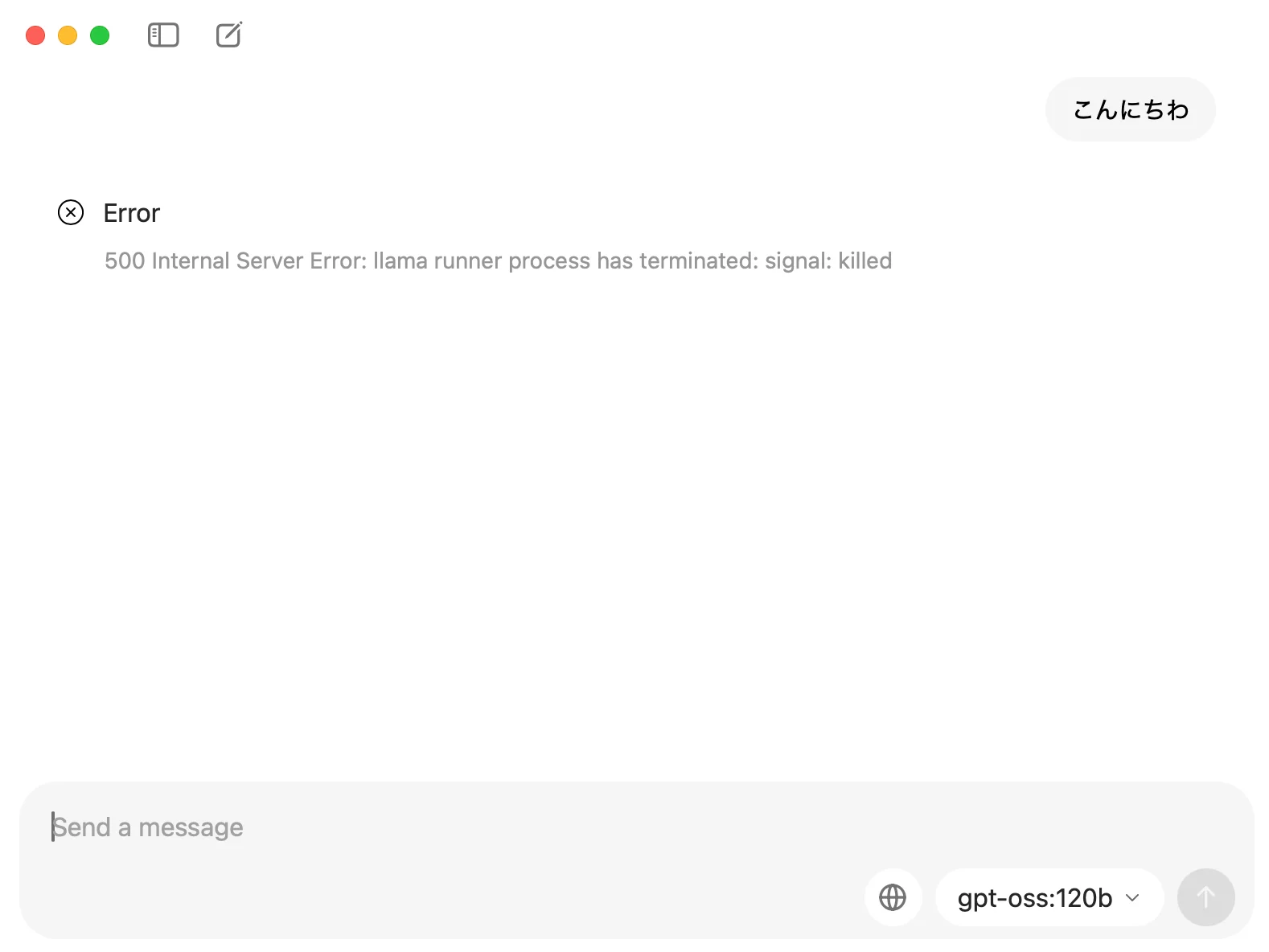
「このクラスのモデルなら、もはやGPUがなくても動くのでは?」と思い、同じようにMacBook Airでも試してみたところ……
しばらく待った後、残念ながらエラーで停止してしまいました。
「gpt-oss:128b」を軽快に動かせるMacBook Proの性能には感心しましたが、やはり学習処理や大規模な演算ではGPUには敵いません。 それでも、MacBook Proをお持ちの方はOllamaと組み合わせて「gpt-oss:128b」をインストールしておくと、飛行機の機内などネットワークが不安定な環境でもChatGPTを利用できるので非常に便利です。