【はじめに】
先日発表されたAmazon S3 Vectors。
週末に空き時間があったので早速ナレッジベースで使ってみました。
と言っても、もう既に他の方々がレビューなどをされているので今更感(まだ一週間も経っていないのに・・・orz)もありますが、単純にナレッジベースも触ったことがなく、以前よりも安価になったと聞いたので。
もしかしたら、ナレッジベースの作り方になるかもしれません(笑)
【システム構成】
主に使用したサービスは以下の通りです。
Amazon S3 汎用バケット
Amazon S3 ベクトルバケット
Amazon Bedrock Knowledge Bases
Amazon Bedrock ベースモデル
- Amazon Titan Text Embeddings V2
- Anthropic Claude Sonnet 4
※ベースモデルの利用には、事前にアクセス申請が必要です。
前提条件として、上記サービスは、すべてバージニア北部(us-east-1)を使用します。
理由としては、原時点(2025/07/20)でAmazon S3 Vectorsが利用できるリージョンが限られているためです。
【ナレッジベース用データの前準備】
まずは、ナレッジベースに使用するデータをPDF形式で作成します。
サンプルとして、弊社に月一で飲み物の補充に来る業者さんの対応手順をPDF化します。
業者対応手順:飲み物業者A
■ 業務内容
・社内の飲み物を月に一度補充する業者
■ 支払い手順
・支払いは現金手渡し
・支払時に領収書をもらう
■ 現金の取り扱い
・支払い用の現金は、金庫内の封筒に保管
・封筒に現金が入っていない場合:
・小口現金を使用する
・金額を経理担当者へ報告する
次にAmazon S3 汎用バケット(バケット名:sample-bucket-2025072001)を作成し、その中に上記PDF化したファイルを保存します。
バケットの設定は、バケット名以外はすべてデフォルトの設定を使用しています。
【ナレッジベースの作成】
「Amazon Bedrock」のコンソール画面を開き、左メニューの「Build」より「ナレッジベース」を開く。
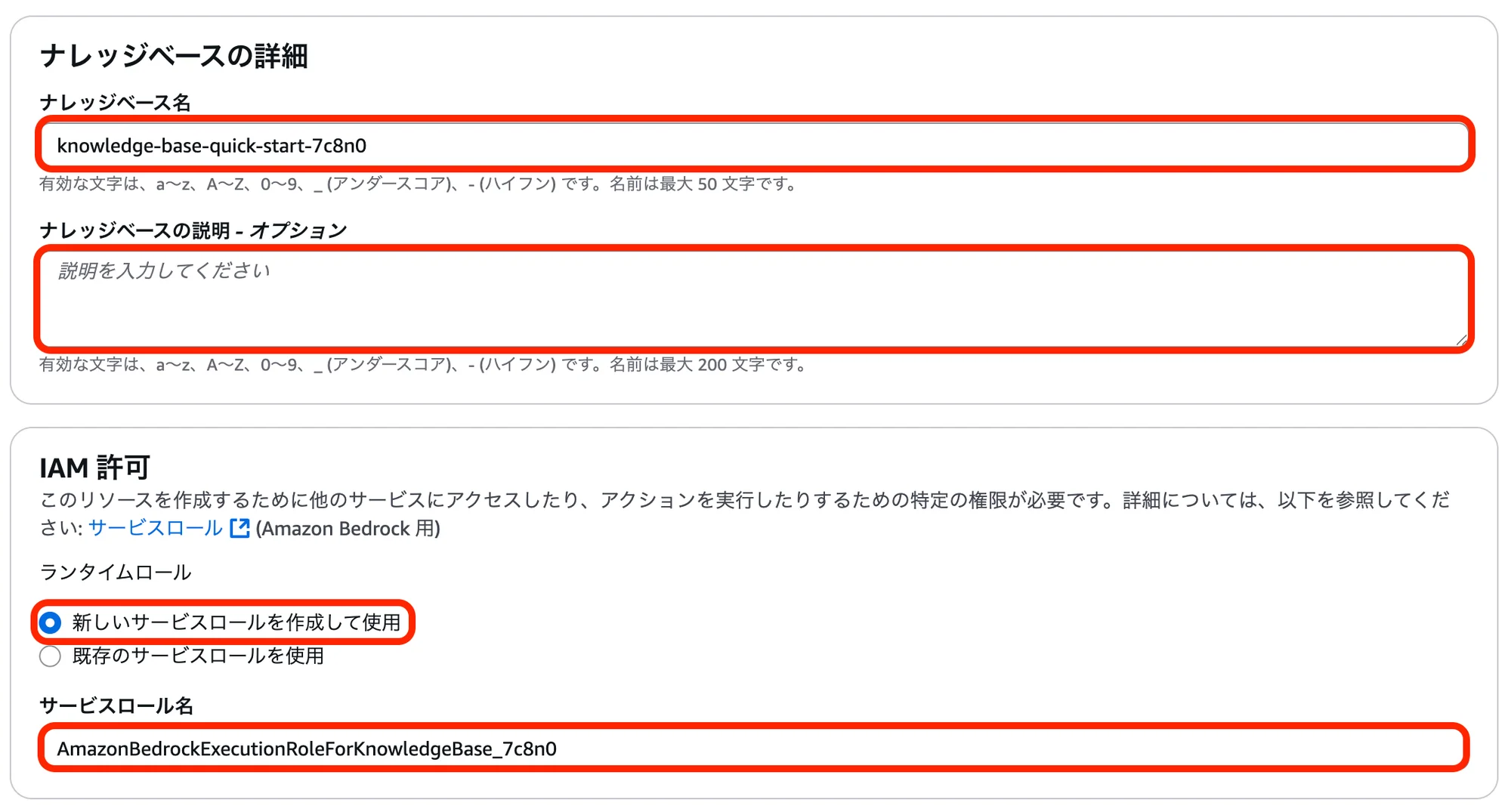
右画面より「作成」をクリックし、「ベクトルストアを含むナレッジベース」を選択。
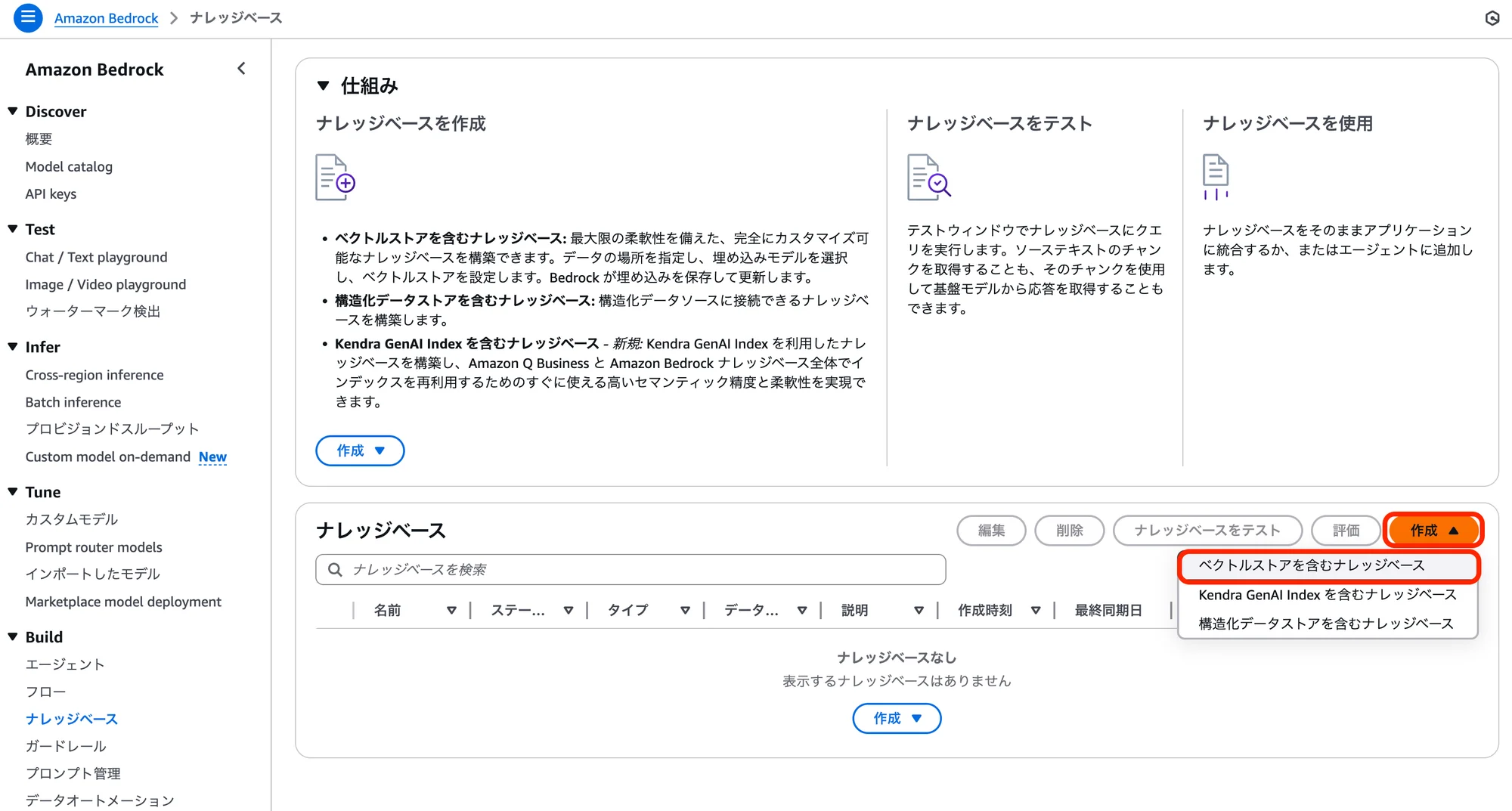
「ナレッジベースの詳細を指定」画面にて、以下の設定・選択を行い「次へ」をクリック。
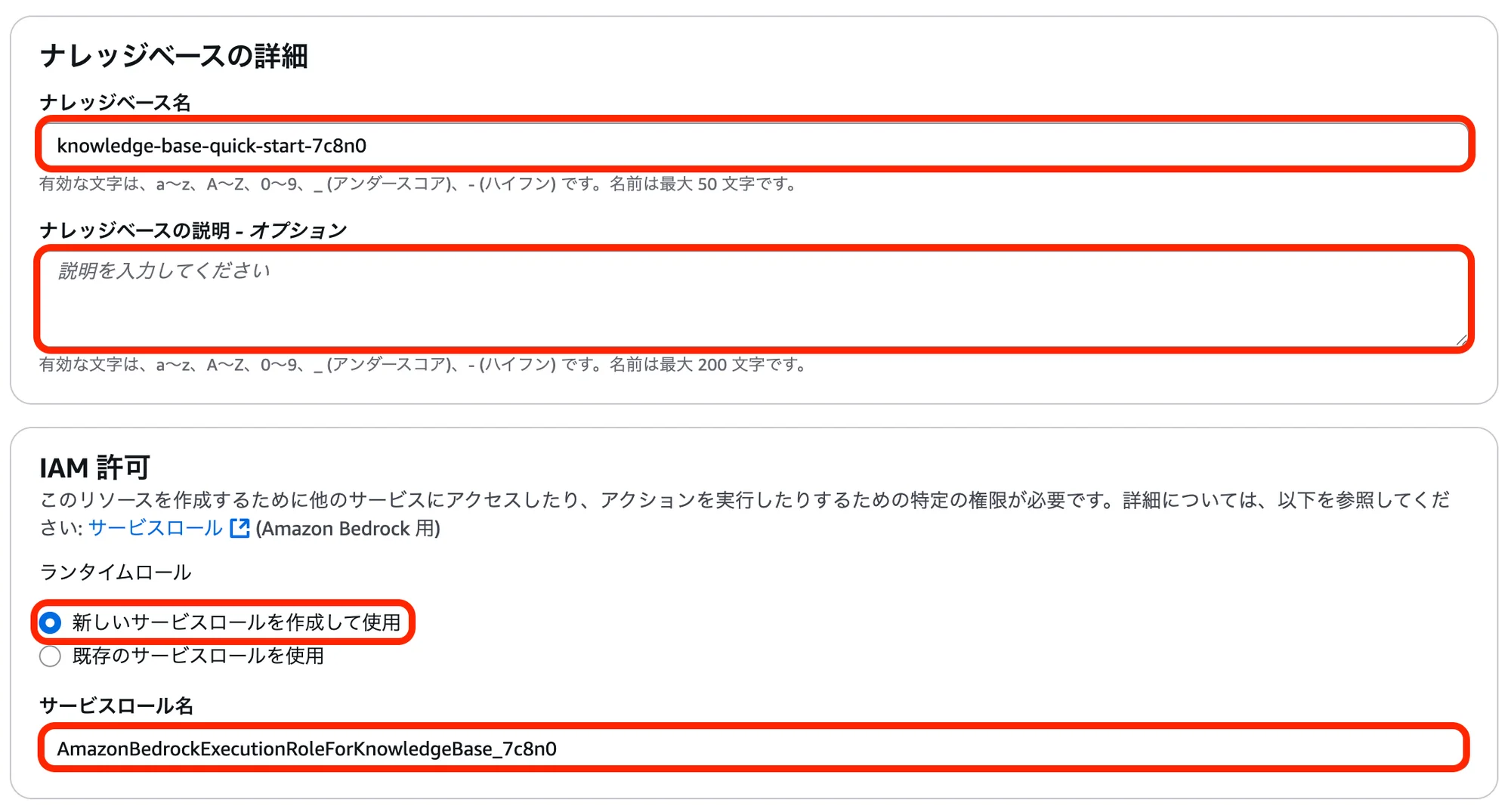
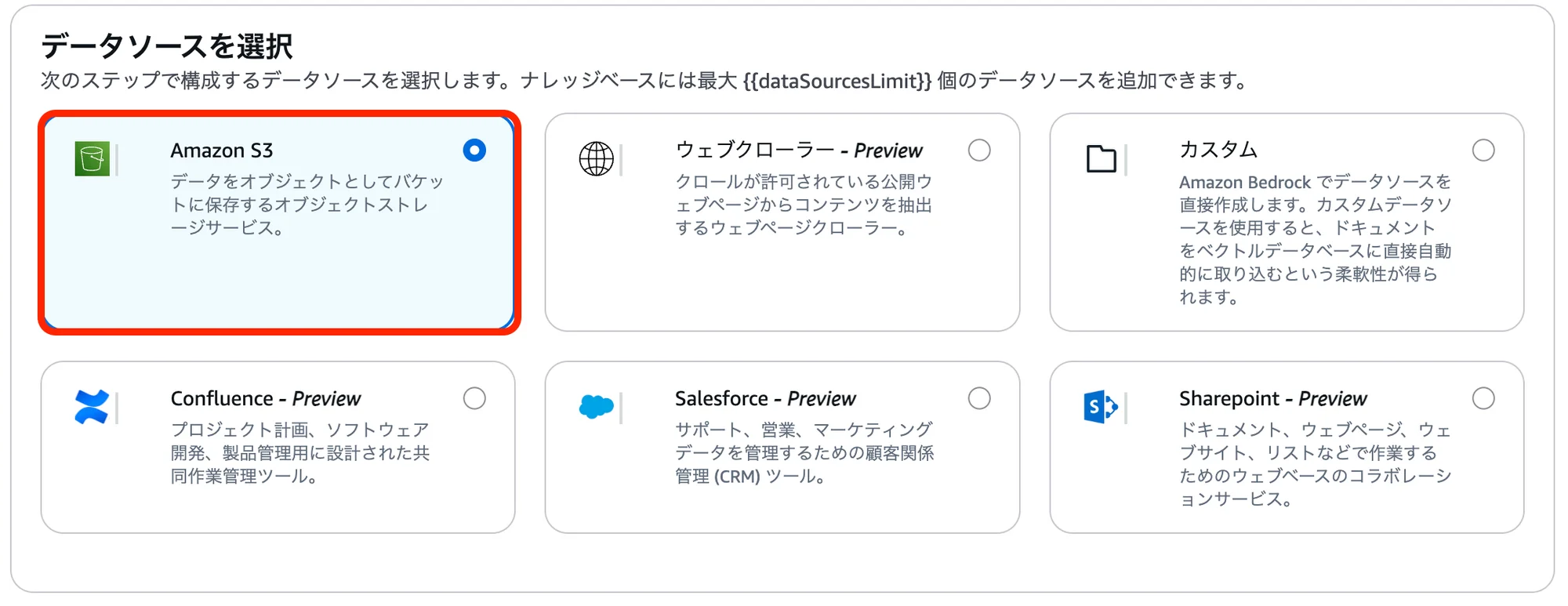
項目名 設定・選択内容 ナレッジベース名 (任意の名前) ナレッジベースの説明 - オプション (必要であれば入力) ランタイムロール 新しいサービスロールを作成して使用 サービスロール名 (任意のロール名) データソースを選択 Amazon S3 上記以外の項目 デフォルト 「データソースを設定」画面にて、以下の設定・選択を行い「次へ」をクリック。
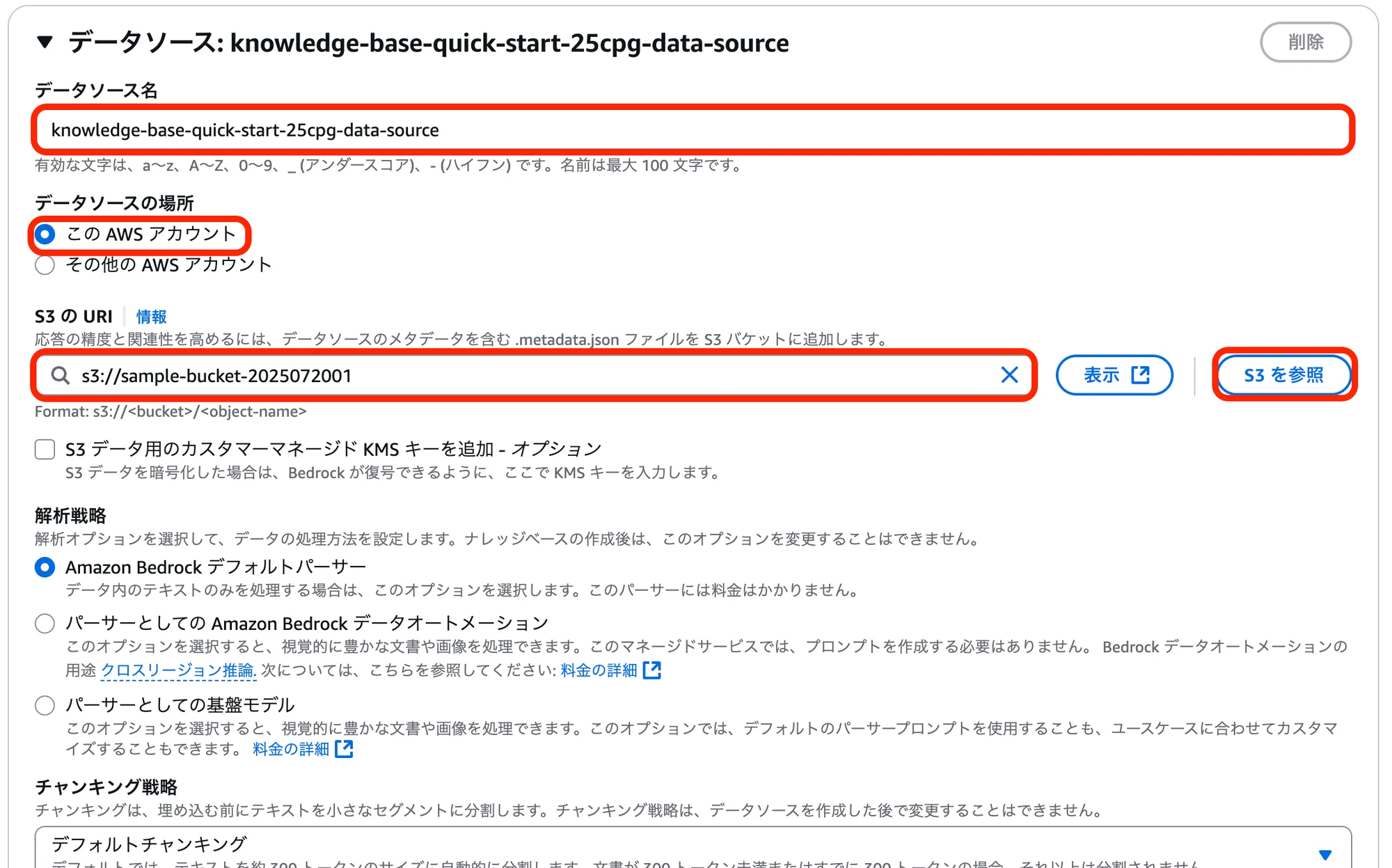
項目名 設定・選択内容 データソース名 (任意の名前) S3のURI s3://sample-bucket-2025072001
(「S3を参照」からPDFファイルを保存したAmazon S3バケットを選択)上記以外の項目 デフォルト 「データストレージと処理を設定」画面にて、以下の設定・選択を行い「次へ」をクリック。
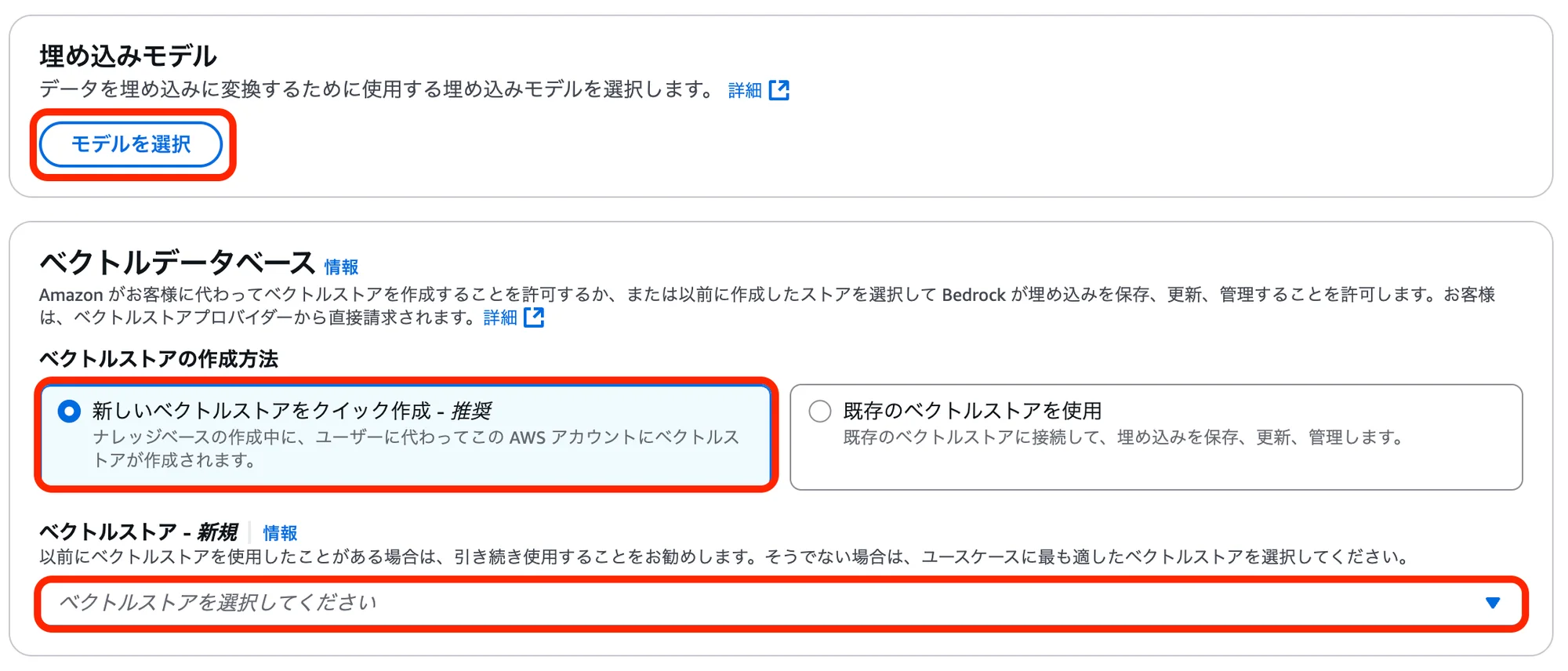
(※モデルとベクトルストアを選択すると、以下のような画面になります。)
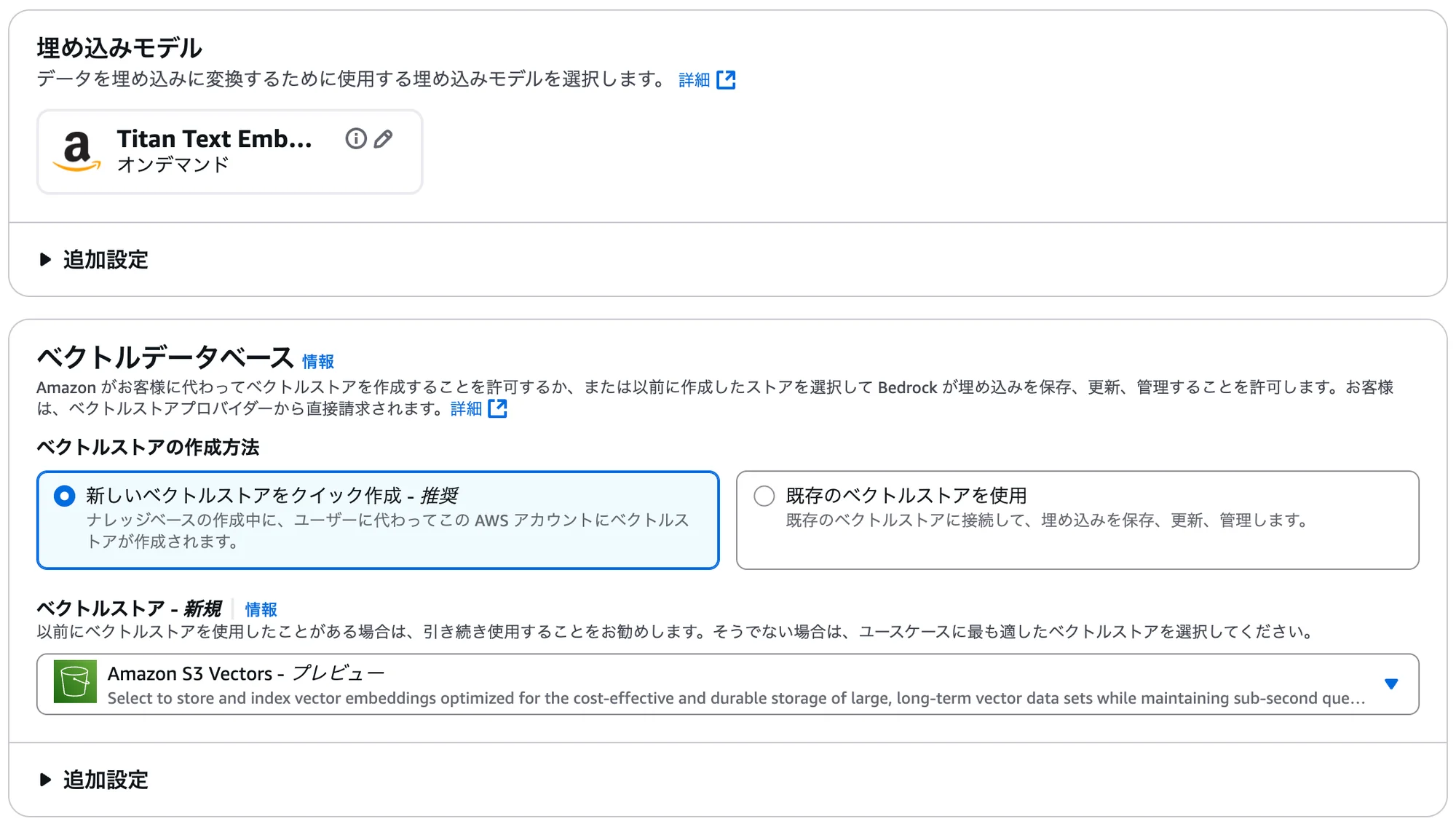
項目名 設定・選択内容 埋め込みモデル モードプロバイダー:Amazon
モデル:Titan Text Embeddings V2
推論:オンデマンドベクトルストアの作成方法 新しいベクトルストアをクイック作成 - 推奨 ベクトルストア - 新規 Amazon S3 Vectors 上記以外の項目 デフォルト 「確認して作成」画面で設定内容を確認し、問題がなければ「ナレッジベースを作成」をクリック。
作成完了まで待つ。作成完了後、画面が遷移。
(この時点では、まだデータの作成は完了していません。)
「データソース」項目にある「データソース名」にチェックを入れ、「同期」をクリック。
(※注意点:先にAmazon Bedrock ベースモデルが利用可能になっていない場合、「同期」をクリックしてもデータの作成が開始されず、エラーになります。その場合は、一旦ベースモデルを利用可能にしてから再度「同期」をクリックしてください。)
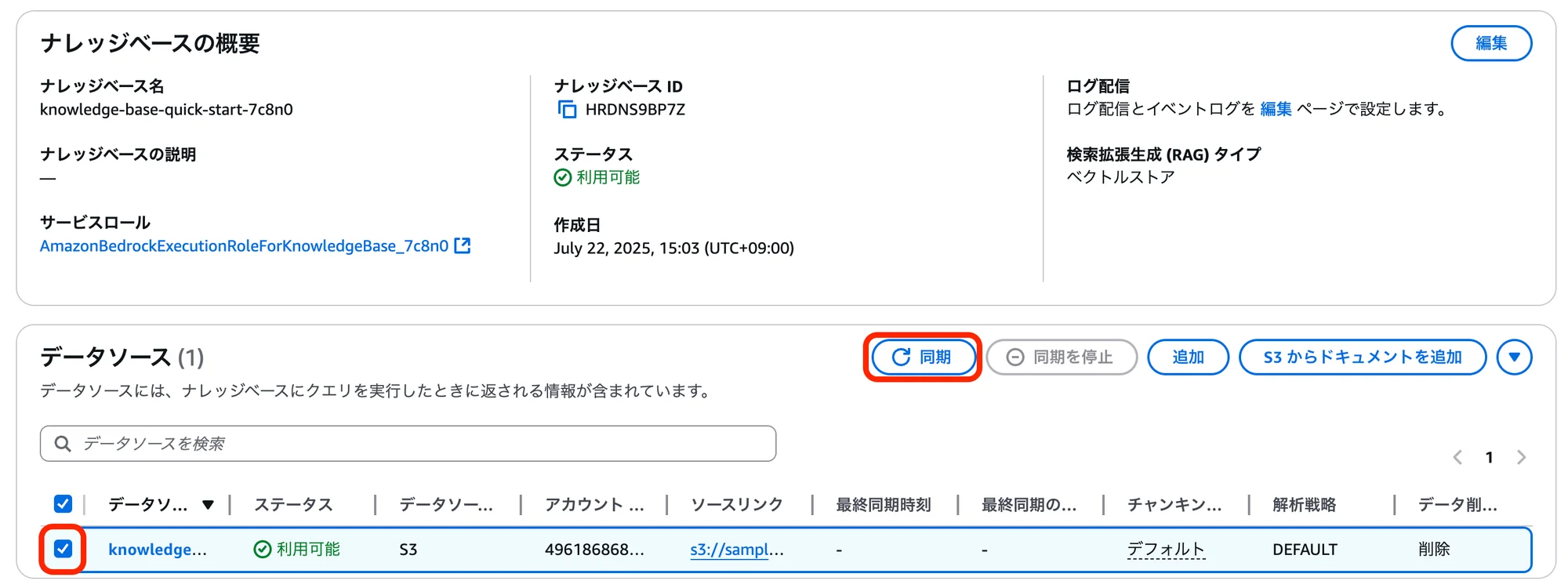
「ステータス」が「同期中」から「利用可能」になるまで暫く待つ。
以上で、作成完了です。
ハマりポイントとしては、先にAmazon Bedrock ベースモデルの利用を可能にしておくこと。
利用可能な状態でなくても途中の埋込モデルを選択できるので、少し紛らわしい
【ナレッジベースのテスト】
作成したナレッジベースのテストを実施し、実際にデータとして取り込めているのかを確認します。
先程の画面(メニューからだと、左メニューのBuild=>ナレッジベース=>ナレッジベース項目にある名前をクリック)の右上にある「ナレッジベースをテスト」をクリックします。
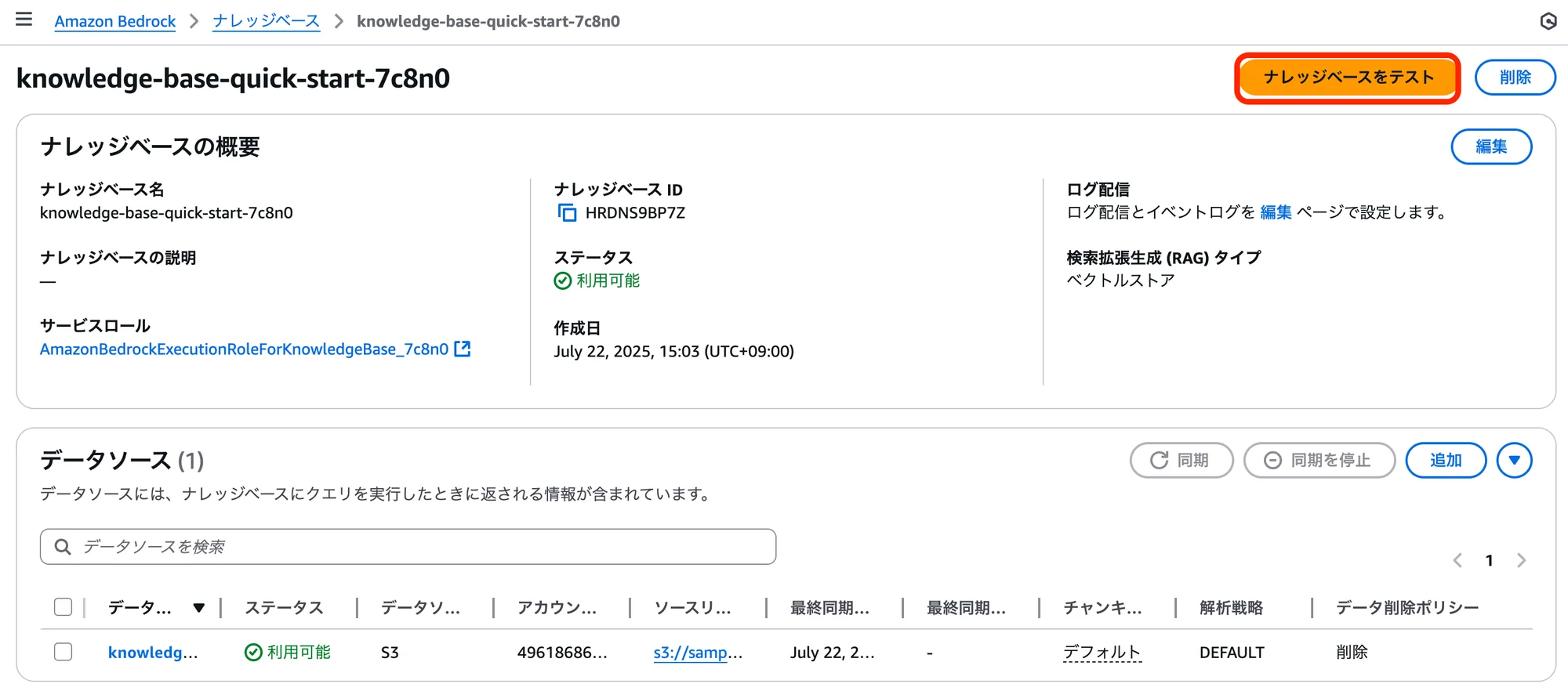
「設定」の「取得と応答生成」項目にある「モデルを選択」をクリックし、モデルを選択する画面を表示し、次を選択、「適用」ボタンをクリックします。
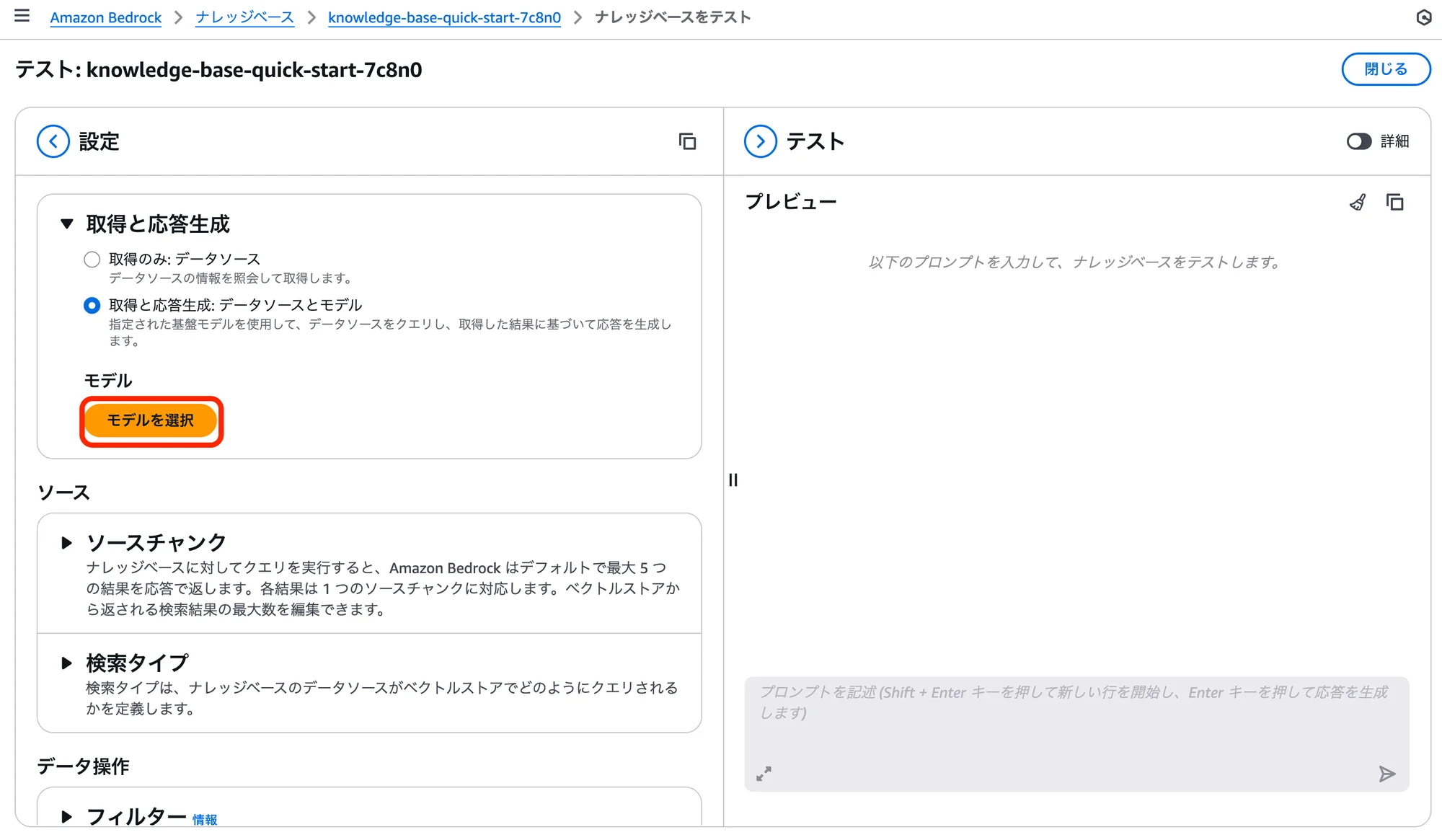
(※モデルを選択すると、以下のような画面になります。)
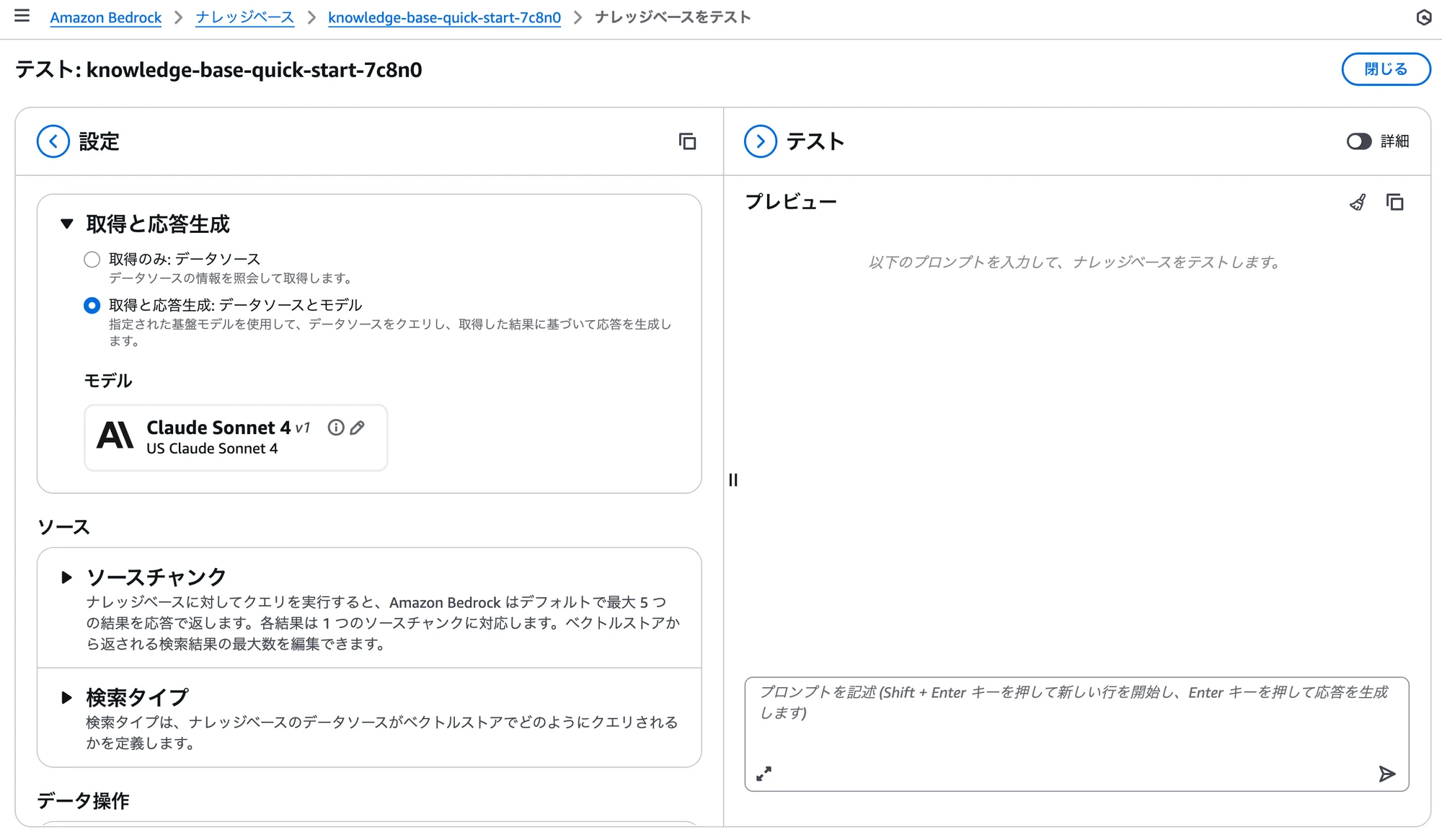
| 項目名 | 設定・選択内容 |
|---|---|
| モデルプロバイダー | Anthropic |
| モデル | Claude Sonnet 4 |
| 推論 | 推論プロファイルのUS Claude Sonnet 4 |
ここでも先にAmazon Bedrock ベースモデルの利用を可能にしておく必要があります。
これでテストの準備が完了です。
「テスト」の項目にあるプロンプトの入力欄に「業者に支払うお金の場所は?」と入力をしてみてください。
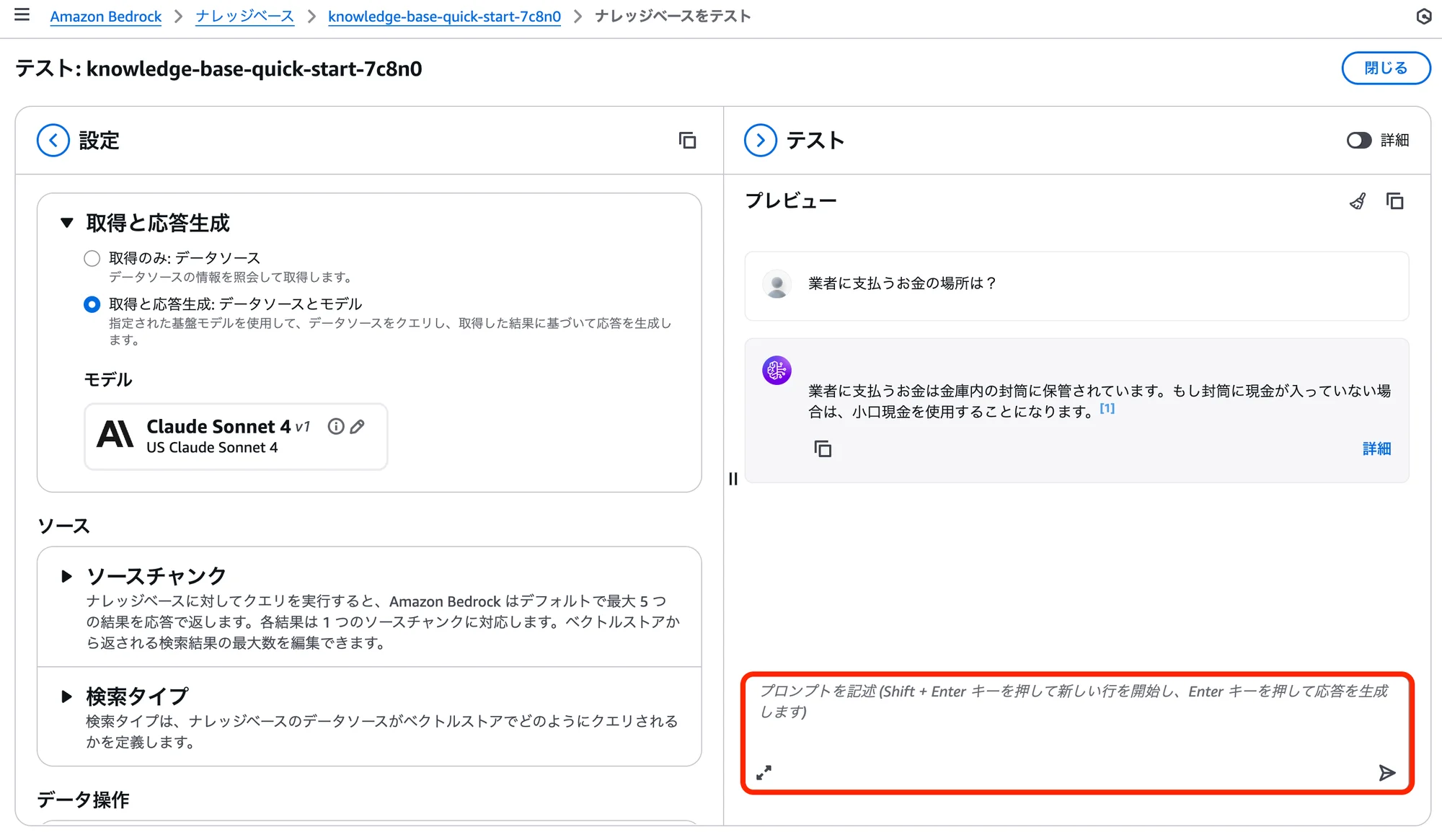
「業者に支払うお金は金庫内の封筒に保管されています。もし封筒に現金が入っていない場合は、小口現金を使用することになります。」といった感じのPDFファイルの内容から取得された情報を基に返答がされます。
【不要なリソースの削除について】
利用料金が安いと言ってもテストも終わったので、今回のテスト環境を削除します。
その際に今回一番のハマりポイントがありました。
大まかに言えば、不要なリソース、設定などは以下の通りです。
- Amazon S3 汎用バケット
- Amazon S3 ベクトルバケット
- ナレッジベース
- IAMロール
- IAMポリシー
ただ単純に削除していけばいいと思っていたのですが、さすがプレビューバージョンのAmazon S3 ベクトルバケット。
今日の時点(2025/07/20)では、Amazon S3 コンソール上から削除はできませんでした。
(※汎用バケット画面とは異なり、画面上部辺りがさみしい感じに・・・。)
では、どうやって削除をするのか?
「AWS CLIでコマンドを叩け!」ということなのですが、ここに大きなハマりポイントが。
CloudeShellからドキュメントで確認した削除コマンドを叩いてみたところ、「コマンドが見つからない」とエラーになりました。
コマンドのバージョンを確認したところ、「バージョン2.27.50」となっているのですが、Amazon S3 Vectorに関するコマンドは、「バージョン2.27.51」から。
なので、現時点では、ローカルPCから「バージョン2.27.51」以降のAWS CLIを使用して、コマンドを叩く必要があります。
ちなみに削除コマンドは、以下の通りです。
通常のS3と同じくバケット内のデータを削除してから、バケットの削除を行う必要があります。
以下は、MacのターミナルからSSO接続を行った状態で使用したコマンドです。
- ベクトルインデックスの削除
aws s3vectors delete-index --vector-bucket-name "(ベクトルバケット名)" --index-name "(ナレッジベースインデックス名)" --region us-east-1 --profile (プロファイル名)
※ナレッジベースインデックス名は、「Amazon S3」の左メニューより、「ベクトルバケット」をクリックし、バケット名をクリックすると表示されます。
- ベクトルバケットの削除
aws s3vectors delete-vector-bucket --vector-bucket-name "(ベクトルバケット名)" --region us-east-1 --profile (プロファイル名)
【まとめ】
実際にAmazon S3 Vectorsを使ってみて感じたのは、PDF1枚というデータでは、金額面以外の差異(精度やパフォーマンス)はほとんど実感できませんでした。
応答もスムーズで、質問にも違和感のない返答がされるので、ナレッジベースを活用していることを意識せずに使える印象でした。
これがもっと大規模なデータや高頻度の質問対応になれば、Amazon S3 Vectorsの性能差や制限が見えてくるかもしれませんが、中小企業の社内ドキュメントや運用マニュアル程度の用途であれば、問題なく使用できるレベルではないかと思います。
「ナレッジベースは高い」というイメージで手を出せていませんでしたが、Amazon S3 Vectorsを使えば金額的ハードルもかなり下がると思います。
最近見かけたGenUでもナレッジベースを使用しており、ナレッジベースを使用すると月額が結構いい値段になると聞いたので、Amazon S3 Vectorsに置き換えたら、もっと手軽に試しやすくなるのではないでしょうか。